

Today, businesses rely heavily on data to make informed decisions, track performance, and remain competitive. Two fundamental methods dominate how organizations gather and exchange information:
Application Programming Interfaces (APIs) and Web Crawlers. While both serve as data access methods, they operate through entirely different mechanisms and serve distinct purposes.
APIs function as structured communication channels between software applications, offering controlled access to specific data sets. Web crawlers, on the other hand, systematically browse the internet to discover and extract publicly available information.
This comprehensive guide will clarify the key differences between API vs web crawler approaches, explain their underlying mechanisms, and demonstrate their critical roles in web development, data science, and digital marketing strategies.
What is an API (Application Programming Interface)?
API is a collection of rules and protocols that allow different software systems to communicate and exchange data efficiently. It works like a contract between two software programs, specifying how they should interact with each other.
How APIs Work
APIs facilitate structured communication through a straightforward process:
- Structured Communication: Applications make targeted requests to specific API endpoints to access certain data or services. These requests follow predetermined formats and include necessary parameters.
- Defined Responses: The API processes incoming requests and returns structured, pre-formatted responses, typically in JSON or XML format. This standardization ensures consistent data delivery.
- Authentication: Most APIs require proper credentials such as API keys, tokens, or authentication protocols to verify authorized access and maintain security.
Purpose and Use Cases
APIs serve multiple critical functions across various industries:
- Controlled Data Access: APIs provide authorized access to specific services or datasets. Weather services, payment processors, and social media platforms all offer APIs for controlled data sharing.
- Service Integration: They enable seamless connections between different systems. E-commerce platforms integrate with shipping providers, inventory management systems, and payment gateways through APIs.
- Application Development: Developers use APIs as building blocks for new software features, avoiding the need to recreate existing functionality from scratch.
APIs offer several key characteristics: explicit permission requirements, highly structured data formats, exceptional reliability, version control capabilities, and typically faster response times for specific queries.
What is a Web Crawler (Web Spider or Bot)?

A web crawler is a software tool designed to navigate the internet systematically, gathering publicly accessible data from various web pages. These digital explorers operate continuously, mapping the internet’s vast content landscape.
How Web Crawlers Work
Web crawlers follow a methodical discovery process:
- Recursive Traversal: Crawlers begin with seed URLs, visit those pages, parse their HTML content, extract new links, and add discovered URLs to their crawling queue for future visits.
- Discovery-Oriented Design: Unlike APIs that access predetermined data, crawlers explore dynamically, adapting to whatever content they encounter across different websites.
- HTML Parsing: Advanced crawlers interpret complex web page code, extracting text, images, metadata, and structural elements while navigating JavaScript-rendered content.
Purpose and Use Cases
Web crawlers serve various essential functions:
- Search Engine Indexing: Search engines such as Google and Bing use bots like Googlebot and Bingbot to create and regularly update their extensive search indexes.
- Data Aggregation: Researchers and businesses use crawlers to collect public information for competitive analysis, market research, and content aggregation.
- Web Archiving: Organizations like the Internet Archive use crawlers to preserve historical versions of websites for future reference.
- SEO Analysis: Digital marketing tools employ crawlers to gather backlink data, monitor keyword rankings, and identify technical SEO opportunities.
Web crawlers operate with distinct characteristics: they access publicly available content without explicit permission (guided by robots.txt files), handle unstructured data requiring complex parsing, can consume significant server resources, and adapt to constantly changing web content.
API vs Web Crawler: Key Differences
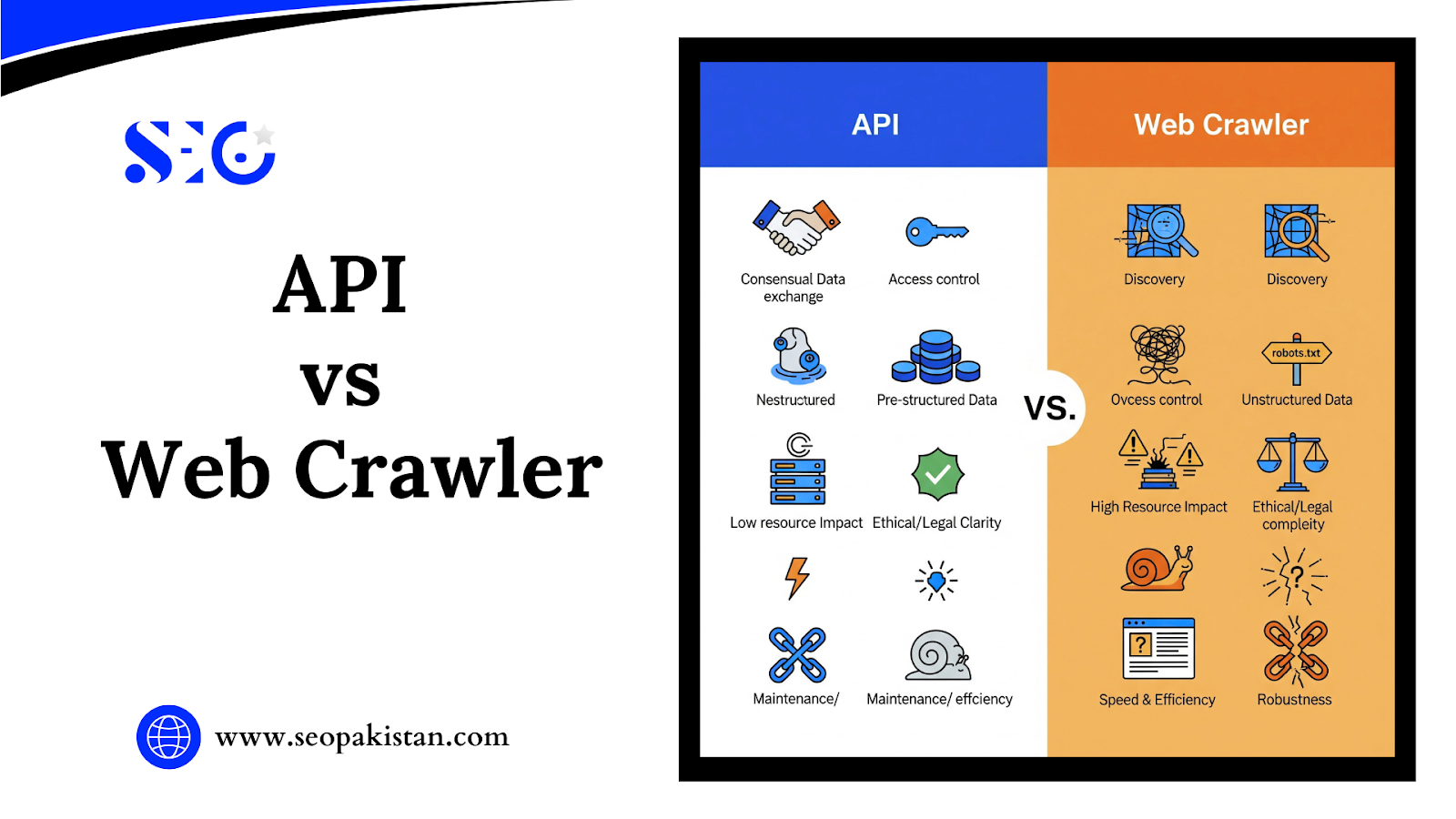
Understanding the fundamental differences between these data access methods helps determine the most appropriate approach for specific projects.
Intent and Relationship
- API: Represents consensual, intentional data exchange where providers specifically design systems for external access. Data owners actively facilitate and control access through documented interfaces.
- Crawler: Operates through discovery and extraction principles, accessing publicly available information that may not be specifically intended for systematic, high-volume collection by third parties.
Access Control and Authorization
- API: Requires explicit permissions through keys, tokens, or authentication systems. Data providers can monitor usage, enforce rate limits, and revoke access when necessary.
- Crawler: Relies on implicit permissions based on public web accessibility. Respects robots.txt guidelines but doesn’t require individual authorization for each interaction.
Data Structure and Format
- API: Delivers pre-structured, predictable data in standardized formats like JSON or XML, making integration straightforward and reliable.
- Crawler: Extracts unstructured data from HTML sources, requiring sophisticated parsing algorithms and constant adaptation to website design changes.
Resource Impact
- API: Generally imposes lower, predictable server loads since data is pre-packaged and optimized for external consumption.
- Crawler: Can create higher, variable server loads, especially when poorly configured or ignoring crawl delay recommendations.
Ethical and Legal Considerations
- API: Typically operates within clear ethical and legal boundaries when users adhere to published terms of service and usage guidelines.
- Crawler: Presents more complex ethical and legal considerations, particularly regarding private data, terms of service violations, and server resource consumption.
Speed and Efficiency
- API: Offers faster, more efficient data retrieval for specific information needs, with real-time capabilities and minimal processing overhead.
- Crawler: Operates more slowly for large-scale data collection due to page rendering, content parsing, and network latency considerations.
Maintenance and Robustness
- API: Provides stable, reliable access with versioned changes and comprehensive documentation for updates.
- Crawler: Requires constant maintenance as website structure changes can easily break extraction logic and data collection processes.
Comparison Table | API vs Web Crawler
| Feature | API | Web Crawler |
| Intent & Relationship | Consensual, intentional data exchange; provider actively facilitates. | Discovery and extraction: access publicly available information. |
| Access Control | Explicit permissions (keys, tokens); monitored & revocable access. | Implicit permissions (robots.txt) rely on public accessibility. |
| Data Structure | Pre-structured, predictable (JSON, XML); easy to parse. | Unstructured (HTML); requires complex parsing; fragile to changes. |
| Resource Impact | Lower, predictable server load; data pre-packaged. | Higher, variable server load; can be resource-intensive. |
| Ethical/Legal | Generally clear; adheres to terms of service. | More complex; depends on data type, terms, and server strain. |
| Speed & Efficiency | Faster, more efficient for specific data; real-time capabilities. | Slower for large-scale data; involves rendering & parsing. |
| Maintenance/Robustness | More stable; versioned changes; documented updates. | Less robust; easily broken by website design/structure changes. |
When to Use Which: Making the Right Choice
Selecting between APIs and web crawlers depends on specific project requirements and available resources.
Choose an API When:
You need structured, consistent data from providers offering public APIs. Real-time data updates are essential for your application’s functionality. Integration goes beyond data collection to include service interactions like payments or user authentication.
Security and authorization are paramount concerns.
APIs work best for building applications requiring reliable, ongoing data access with minimal maintenance overhead.
Choose a Web Crawler When:
No suitable API exists for the public data you need to collect. Your project requires information gathering across multiple, diverse websites simultaneously. The target data exists within unstructured web content like blog posts, product descriptions, or news articles.
Your primary goal involves the discovery and indexing of broad web content categories.
Web crawlers excel at large-scale data discovery projects where flexibility and comprehensive coverage outweigh speed and structure concerns.
Their Role in SEO and Digital Strategy
Both APIs and web crawlers play crucial roles in modern digital marketing and SEO strategies.
APIs in SEO and Digital Marketing
- Google Analytics API: Enables extraction of detailed website performance metrics for custom dashboards, automated reporting, and advanced analysis beyond standard interface limitations.
- Google Search Console API: Provides programmatic access to search performance data, including query information, impression counts, click-through rates, and indexing status updates.
- Social Media APIs: Facilitate integration of sharing functionality, content feeds, and social sentiment analysis into websites and marketing platforms.
- E-commerce APIs: Connect product catalogs, inventory systems, and order management platforms to optimize product visibility and streamline operations.
Web Crawlers in SEO and Digital Marketing
- Search Engine Crawlers: Form the foundation of organic search functionality. SEO professionals optimize websites specifically to help crawlers like Googlebot understand and properly index content.
- SEO Tool Crawlers: Platforms like Ahrefs, SEMrush, and Moz deploy specialized crawlers to gather competitive intelligence, monitor backlink profiles, and identify technical optimization opportunities.
- Website Monitoring Systems: Automated crawlers continuously check site performance, uptime, and technical health, indirectly supporting SEO efforts by preventing ranking-damaging downtime.
Conclusion
So, what’s the big takeaway from our chat about API vs web crawler? It really comes down to how they grab data. APIs give you a structured, clear, and authorized way for software to talk. They deliver exact, pre-arranged data.
Web crawlers, on the other hand, are all about broad discovery. They explore and extract publicly available web content. This data is often unstructured. Both tools are super important in our digital world today. Crawlers are great for things like search engine indexing. APIs shine in smooth service integrations.
Knowing these differences helps you pick the best and most ethical method for your data. Are you aiming for better search visibility? Or do you need to integrate powerful new features? Using these tools wisely is key to digital success. Need expert help with your data strategy and SEO? Just contact SEO Pakistan today!
Frequently Asked Questions
Can I use a web crawler if an API is available?
While technically possible, using official APIs is generally preferred. APIs offer more reliable, efficient, and ethical data access that respects provider intentions and typically aligns with terms of service requirements.
Is web scraping using crawlers legal?
Web scraping legality varies by jurisdiction and specific circumstances. It’s generally acceptable for publicly available data when it doesn’t violate copyright laws, terms of service, privacy regulations like GDPR, or cause excessive server strain. Always review robots.txt files and website terms before proceeding.
What is robots.txt, and how does it relate to crawlers?
Robots.txt is a standardized text file that instructs web crawlers about which website sections they should or shouldn’t access. It serves as guidance for legitimate crawlers like search engine bots, though malicious crawlers may ignore these directives.
Are all bots web crawlers?
No. While all web crawlers are bots, the bot category includes many other automated programs: chatbots, social media bots, spam bots, and malicious bots like those used in DDoS attacks. Each serves different purposes beyond web content discovery.











