

The internet houses over 1.7 billion websites, creating an endless repository of valuable information. But how do businesses, researchers, and search engines efficiently collect and utilize this vast digital landscape?
Two fundamental techniques dominate web data extraction: web crawling and web scraping. These methods power everything from Google’s search results to price comparison websites and market research platforms. Yet despite their widespread use, many professionals mistakenly treat these terms as interchangeable.
Understanding the web crawling vs web scraping distinction is essential for anyone involved in digital marketing, data analysis, or web development. Each serves unique purposes, employs different methodologies, and requires distinct approaches to implementation and compliance.
This comprehensive guide will clarify these concepts, explore their core differences, and explain how they work together to unlock the web’s potential. You’ll discover when to use each technique, what tools are available, and how to navigate the ethical and legal considerations that surround web data extraction.
What is Web Crawling? The Discovery Engine
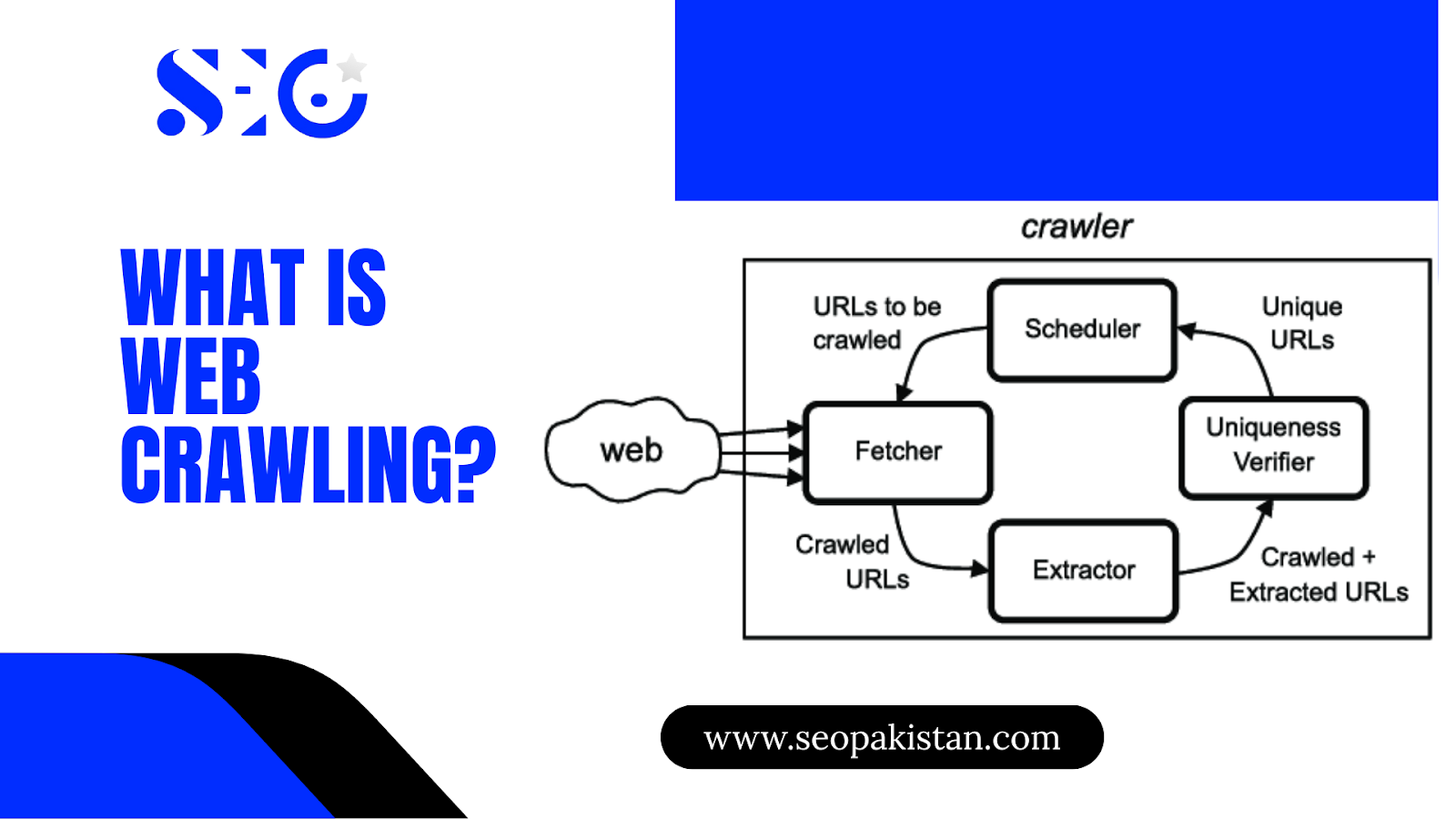
Web crawling represents the automated process of systematically discovering and indexing web pages across the internet. Think of it as a digital explorer that maps the web’s vast territory, following links from page to page to understand the structure and content of websites.
Purpose
Search engines rely heavily on web crawling to maintain their massive indexes. Google’s Googlebot continuously crawls billions of web pages, discovering new content and updating existing entries to ensure search results remain current and comprehensive.
Beyond search engines, web crawling serves several critical functions:
- Web Archiving: Organizations like the Internet Archive use crawlers to preserve digital content for historical research and cultural preservation
- Link Analysis: Understanding how websites connect to each other helps identify authoritative sources and detect spam networks
- Website Monitoring: Businesses use crawling to track changes across their digital properties and monitor competitor activities
How it Works
- Web crawling starts with a set of seed URLs, which act as the starting points for discovering content.
- Crawlers follow hyperlinks on these pages, both internal and external, to build a network of interconnected content.
- The process adheres to website boundaries defined by robots.txt files, which specify areas that crawlers can or cannot access.
- XML sitemaps provide structured guides to help crawlers discover pages more efficiently.
- Modern crawlers work continuously, revisiting pages to detect updates while also exploring new pages.
- This systematic approach ensures thorough coverage of the constantly changing web.
Key Characteristics
Web crawling operates with a broad scope and a discovery-focused methodology. Unlike targeted data extraction, crawlers cast wide nets to map entire websites or sections of the internet. Their primary output consists of URL lists and page content suitable for indexing rather than specific data points.
Tools/Technologies
Search engine operators develop sophisticated crawling systems, but open-source alternatives exist for specialized needs:
- Apache Nutch: Enterprise-grade crawling framework for large-scale operations
- Python Libraries: Requests and urllib enable custom crawling solutions
- Commercial Crawlers: Specialized tools for business intelligence and competitive analysis
Use Cases
Web crawling is highly effective for tasks involving extensive discovery and mapping. Search engines depend on crawling to build comprehensive indexes. Businesses use crawlers for website health monitoring, identifying broken links, and conducting competitive analysis across entire industry sectors.
What is Web Scraping? The Data Extraction Specialist

Web scraping is the process of extracting structured and targeted information from specific websites. Rather than exploring broadly like crawling, scraping operates with surgical precision to collect particular information elements for analysis and processing.
Purpose
This targeted approach enables businesses to collect product prices, contact information, news headlines, and other specific data points that drive decision-making processes.
This structured approach makes scraped information suitable for databases, spreadsheets, and analytical tools.
How it Works
Web scraping begins with predetermined target URLs, often identified through previous crawling activities. The process involves parsing HTML structures to locate and extract desired elements using CSS selectors or XPath expressions.
Modern websites frequently rely on JavaScript for content rendering, requiring specialized tools:
- Headless Browsers: Puppeteer and Selenium execute JavaScript to access dynamically generated content
- API Integration: Many websites offer official APIs as alternatives to scraping, providing more reliable data access
- DOM Analysis: Scrapers analyze document object models to identify consistent patterns for data extraction
Key Characteristics
Web scraping operates with a narrow focus and precise methodology. Success depends on understanding website structures and adapting to layout changes. The output consists of structured data formats like CSV files, JSON objects, or direct database entries.
Tools/Technologies
Python dominates the web scraping landscape with powerful libraries designed for different complexity levels:
- BeautifulSoup: Perfect for basic HTML parsing and small-scale tasks
- Scrapy: Enterprise framework for complex, large-scale scraping operations
- Selenium: Handles JavaScript-heavy websites requiring browser automation
- Puppeteer: Node.js solution for dynamic content scraping
Use Cases
Web scraping powers numerous business applications requiring specific data collection. E-commerce companies monitor competitor pricing, marketing teams generate leads from directory websites, researchers gather data for academic studies, and news aggregators collect headlines from multiple sources.
Key Differences: Crawling vs. Scraping
Web scraping and crawling are related but distinct processes used in data extraction from the web: web scraping extracts specific data from websites, while web crawling discovers and indexes URLs to facilitate scraping or indexing. Together, they optimize data retrieval for applications like SEO, analytics, and market research.
| Aspect | Web Scraping | Web Crawling |
|---|---|---|
| Definition | Extracting specific data from selected web pages by parsing and processing their content. | Automatically browsing websites to discover, index, and catalog URLs and page structures. |
| Purpose | Retrieve targeted information such as product prices, reviews, or contact details for analysis. | Explore, map, and index web pages broadly to create searchable indexes or gather metadata. |
| Scope | Focused on specific pages or sections of a website where data is extracted. | Broad and systematic coverage of entire websites or multiple sites by following links recursively. |
| Process | Download HTML pages of interest and parse them to extract structured data in formats like JSON or CSV. | Start from seed URLs, follow hyperlinks to discover and queue new URLs, repeatedly visiting web pages. |
| Output | Structured data ready for analysis, stored locally or in databases. | List of URLs, page metadata, and content indexes without extracting detailed content. |
| Frequency/Scale | Often on-demand or periodic, can be small-scale or large-scale depending on needs. | Usually continuous or large-scale, supporting search engine indexing or large website audits. |
| Complexity | Requires handling site-specific layouts, dynamic content, pagination, CAPTCHAs, and anti-bot defenses. | Requires efficient traversal algorithms, duplicate URL filtering, prioritization, and politeness policies. |
| Typical Tools | BeautifulSoup, Scrapy (scraping mode), Selenium, Puppeteer. | Apache Nutch, Scrapy (crawling mode), Googlebot, Screaming Frog, Heritrix. |
| Use Cases | Price comparison, lead generation, market research, data monitoring, content aggregation. | Search engine indexing, website audits, link discovery, monitoring website changes. |
| Legal/Ethical Concerns | Must respect website terms of service and copyright; often require permission or API usage. | Must obey robots.txt directives and crawl politely to avoid overloading servers. |
| Relation | Usually follows crawling; scraping extracts data from pages discovered by crawlers. | Can work standalone or as part of scraping workflows to discover pages for scraping. |
| Data Granularity | Extracts detailed, targeted content (e.g., product name, price). | Collects metadata and webpage URLs broadly without focusing on detailed content extraction. |
| Automation Level | Scripted or tool-based, sometimes manual intervention for complex pages. | Fully automated bots running recursively to cover link graphs expansively. |
| Performance Focus | Accuracy and robustness in extracting relevant data despite webpage changes. | Efficiency in covering URLs quickly while avoiding duplicate crawling and respecting crawl delays. |
| Output Use | Feeding analytics dashboards, data science models, decision-making apps. | Powering search engines, site structure analysis, competitive intelligence. |
The Interplay: How They Relate
Web crawling and scraping often work in tandem rather than in isolation. Understanding their relationship helps optimize data collection strategies and resource allocation.
Crawling as a Prerequisite
Many scraping projects begin with crawling phases to identify target URLs. For example, an e-commerce price monitoring system might first crawl competitor websites to discover product pages, then scrape specific pricing information from each discovered URL.
This two-stage approach ensures comprehensive coverage while maintaining extraction precision. The crawling phase maps available content, while scraping extracts valuable data points from identified sources.
Scraping within Crawling
Advanced crawling systems now include light scraping features to enhance indexing processes. This means that search engines don’t just find new pages; they also extract key metadata, identify page topics, and assess content quality all at once.
- Advanced crawling systems now incorporate light scraping features to improve indexing efficiency.
- Search engines not only discover new pages but also extract key metadata, identify page topics, and evaluate content quality during crawling.
- This hybrid approach combines discovery and data extraction, saving time and resources.
- For example, crawlers collect page titles, descriptions, and keywords to better understand site relevance and purpose.
- As a result, search engines deliver more accurate and higher-quality search results to users.
- Website owners should optimize metadata, maintain strong content, and ensure proper site structure to enhance discoverability and rankings.
Distinct but Complementary
Crawling and scraping are two essential tools for building effective web data solutions, each serving a unique purpose. Crawling focuses on discovering and indexing a wide range of web pages, giving you the breadth needed to understand the scope of available data.
On the other hand, scraping dives deeper, extracting specific pieces of information from those pages, and adding depth and detail to your data.
When used together strategically, crawling helps you identify valuable content across the web, while scraping ensures you capture the exact data points you need. For example, a crawler might help you locate all e-commerce pages selling a particular product, and a scraper can then extract product prices, descriptions, and reviews from those pages.
To build a robust data strategy, start by clearly defining your goals. Are you looking for general insights or highly specific information? Use crawling to map out the web landscape first, then implement scraping to gather precise details.
Together, these techniques can provide the comprehensive, actionable data needed to drive smarter decisions in marketing, research, or business development.
Why Differentiate? Importance for SEO and Beyond
Understanding the distinction between web crawling and scraping impacts multiple aspects of digital strategy, from technical implementation to legal compliance.
For SEO Professionals
Search engine optimization requires a deep understanding of how crawlers operate and index content. SEO professionals must optimize websites for crawler accessibility while respecting the boundaries between discovery and extraction.
Key considerations include:
- Crawler Optimization: Ensuring Googlebot can efficiently discover and index website content
- Ethical Data Collection: Avoiding scraping practices that could damage the website’s reputation or violate the terms of service
- Competitive Analysis: Using scraping responsibly for market insights without crossing ethical boundaries
For Businesses and Developers
Choosing appropriate tools and methodologies depends on specific data requirements and resource constraints. Different projects demand different approaches, and understanding these distinctions prevents costly mistakes and inefficient implementations.
Critical factors include:
- Tool Selection: Matching technology choices to project requirements and complexity levels
- Resource Management: Understanding computational and network demands for each approach
- Legal Compliance: Navigating robots.txt files, terms of service agreements, and data privacy regulations
Conclusion
Understanding the web scraping vs. crawling difference is key to unlocking the full potential of web data. Crawling focuses on discovering and mapping the web, providing a comprehensive view of structure and content.
On the other hand, scraping extracts specific, actionable data to fuel business intelligence. Together, they complement each other, forming a powerful strategy for leveraging online information.
By balancing these considerations, businesses can optimize for search engines, conduct market research, and build data-driven applications responsibly.
Ready to take your web data strategies to the next level? Visit SEO Pakistan to learn more about effective and ethical approaches to web scraping vs. crawling, and discover how we can help you achieve your data and SEO goals.
Frequently Asked Question
Is Googlebot a crawler or a scraper?
Googlebot is primarily a web crawler. Its main purpose is to explore and map the web, finding new and updated content for Google’s search index. While it does extract some information for indexing, its core function isn’t specific data harvesting but broad discovery.
Can scraping occur without crawling?
Yes, web scraping can be executed without an explicit crawling phase if you already possess a precise list of URLs from which to extract data. However, for large-scale projects or to discover new data sources, a preliminary crawling stage often precedes the scraping process to identify relevant pages.
What are common uses of web crawling?
Web crawling is mainly used for search engine indexing, web archiving, and monitoring website changes for broad site analysis.
What are common uses of web scraping?
Web scraping is used for market research, lead generation, price monitoring, and collecting specific data for analysis from targeted web pages.
What are popular web scraping and crawling tools?
- For scraping, tools include Beautiful Soup, Scrapy, and Selenium.
- For crawling, Apache Nutch and search engine proprietary crawlers are common.











